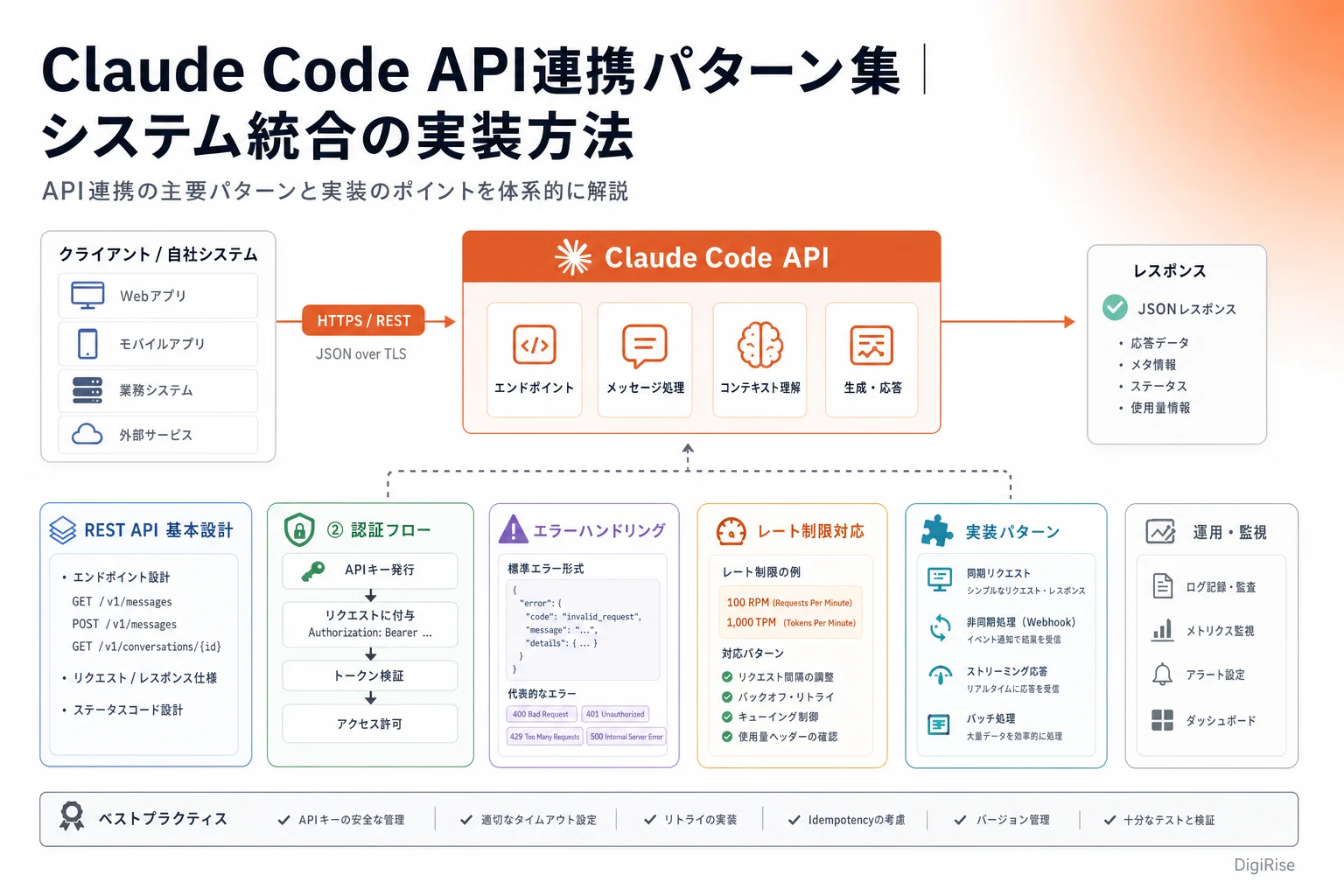
私が法人向けに Claude Code の API 連携を支援してきた経験の中で、最も多く寄せられる質問が「どのようなアーキテクチャで統合すれば安定稼働が見込めるか」というものです。Claude API の公式ドキュメントは充実していますが、実際のシステム統合では認証設計、エラーハンドリング、非同期処理の設計など、現場特有の判断が求められます。本記事では、DigiRise が複数の法人案件で検証してきた API 連携パターンを、疑似コードを交えながら解説します。社内システムとの統合設計を検討されている技術リードの方に、実装の判断材料を提供することを目的としています。
本記事の結論: Claude API 連携では認証管理・リトライ設計・監査ログ取得の3点を明確にすることで、安定稼働の基盤が整う
Claude API の基本構成と認証方式
Claude API は REST 形式で提供されており、リクエストには API キーによる認証が必要です。Anthropic が公式に提供する認証方式は API Key 方式のみで、Bearer トークンとしてヘッダーに含めます。OAuth2 や SAML といった外部 IdP 連携は現時点では公式にサポートされていないため、キー管理は自社の責任範囲となります。
認証実装の基本パターン
# 疑似コード(Python 風)
import os
import requests
API_KEY = os.environ.get("ANTHROPIC_API_KEY")
ENDPOINT = "https://api.anthropic.com/v1/messages"
headers = {
"x-api-key": API_KEY,
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
payload = {
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "ユーザーの質問"}
]
}
response = requests.post(ENDPOINT, headers=headers, json=payload)API キーの管理: 環境変数や AWS Secrets Manager・Azure Key Vault などのシークレット管理サービスでキーを保護する運用が推奨される。ソースコードへの直接埋め込みは避ける
API バージョンは anthropic-version ヘッダーで指定します。Anthropic は定期的に新バージョンをリリースするため、最新の仕様を公式ドキュメントで確認し、段階的に移行する計画を立てることが望ましいです。
レート制限とクォータ管理
Claude API にはリクエスト数・トークン数の上限が設定されています。具体的な制限値は契約プランや組織の利用状況により異なるため、Anthropic の管理コンソールで確認する必要があります。私が支援した事例では、レート制限に達した際に 429 Too Many Requests が返されるため、Exponential Backoff によるリトライ設計を実装しています。
リクエスト設計と非同期処理パターン
Claude API は同期型の REST エンドポイントですが、業務システムとの統合では非同期処理の設計が求められるケースが多くあります。特に、ユーザーからの問い合わせ対応やドキュメント解析など、処理時間が不定な場合には、キュー型のアーキテクチャを検討する価値があります。
同期連携の基本フロー
最もシンプルな統合パターンは、ユーザーのリクエストを受けてその場で Claude API を呼び出し、結果を返す同期処理です。社内チャットボットや FAQ システムなど、即時性が求められる用途に適しています。
# 疑似コード(同期処理)
def chat_endpoint(user_message: str):
response = call_claude_api(user_message)
if response.status_code == 200:
return response.json()["content"][0]["text"]
else:
return handle_error(response)ただし、Claude API の応答時間は入力トークン数や生成内容に応じて変動するため、タイムアウト設定(30秒程度)を設けることが推奨されます。
非同期連携パターン(キュー+ワーカー)
長時間の処理や大量リクエストを捌く場合、キュー+ワーカー型のアーキテクチャが安定性を高めます。AWS SQS や Azure Service Bus、Redis Queue などのメッセージキューにリクエストを積み、バックグラウンドワーカーが順次処理する設計です。
1. リクエスト受付 — Web API がユーザーリクエストを受け取り、ジョブ ID を発行してキューに投入
2. ワーカー処理 — バックグラウンドワーカーがキューからジョブを取得し、Claude API を呼び出し
3. 結果保存 — 応答内容をデータベースまたはオブジェクトストレージに保存
4. 通知 — Webhook や WebSocket でクライアントに結果を通知
# 疑似コード(非同期処理)
import uuid
from queue import Queue
job_queue = Queue()
def submit_job(user_message: str):
job_id = str(uuid.uuid4())
job_queue.put({"job_id": job_id, "message": user_message})
return {"job_id": job_id, "status": "queued"}
def worker():
while True:
job = job_queue.get()
response = call_claude_api(job["message"])
save_result(job["job_id"], response)
notify_client(job["job_id"])この設計により、API レート制限に対する耐性が高まり、ピーク時のリクエスト集中にも柔軟に対応できます。
エラーハンドリングとリトライ戦略
Claude API との連携では、ネットワーク障害や一時的なサービス過負荷による失敗が発生する可能性があります。安定稼働を確保するため、適切なエラーハンドリングとリトライロジックの実装が不可欠です。
HTTP ステータスコード別の対応方針
| ステータスコード | 意味 | 推奨対応 |
|---|---|---|
| 200 OK | 成功 | 正常処理 |
| 400 Bad Request | リクエスト形式の誤り | ログ記録し、リトライしない |
| 401 Unauthorized | API キー無効 | 認証情報を確認、リトライしない |
| 429 Too Many Requests | レート制限超過 | Exponential Backoff でリトライ |
| 500 Internal Server Error | サーバー側エラー | リトライ(最大3回程度) |
| 503 Service Unavailable | サービス一時停止 | リトライ(間隔を長めに設定) |
リトライ設計の実装例
# 疑似コード(Exponential Backoff)
import time
MAX_RETRIES = 3
BASE_DELAY = 2 # 秒
def call_claude_with_retry(payload):
for attempt in range(MAX_RETRIES):
response = requests.post(ENDPOINT, headers=headers, json=payload)
if response.status_code == 200:
return response
elif response.status_code == 429 or response.status_code >= 500:
if attempt < MAX_RETRIES - 1:
delay = BASE_DELAY * (2 ** attempt)
time.sleep(delay)
else:
raise Exception("Max retries exceeded")
else:
# 4xx エラーはリトライ不可
raise Exception(f"API error: {response.status_code}")リトライ間隔の設計: 指数バックオフにより、サーバー側の負荷を軽減しながら再試行を行う。初回2秒、2回目4秒、3回目8秒といった間隔が一般的
リトライ回数や間隔は、自社のサービス要件(許容される遅延時間、リクエスト頻度)に応じて調整する必要があります。私が支援した案件では、最大3回のリトライと10秒のタイムアウトを基本設定とし、業務特性に応じて微調整を行っています。
監査ログ取得と MCP 連携
法人利用において、Claude API の利用状況を記録し、監査可能な状態を保つことは重要な要件です。Anthropic が提供する Claude for Enterprise では、管理コンソールから基本的な利用ログを確認できますが、詳細な監査要件(誰が・いつ・何を・どのように利用したか)を満たすには、アプリケーション側での記録設計が必要です。
監査ログに記録すべき項目
- リクエスト元: ユーザー ID、部署、IP アドレス
- タイムスタンプ: リクエスト受付時刻、API 呼び出し時刻
- 入力内容: プロンプト全文(機密情報のマスキング処理を考慮)
- 応答内容: 生成されたテキストの全文
- メタデータ: 使用モデル、トークン数、処理時間
# 疑似コード(監査ログ記録)
import json
import datetime
def log_audit(user_id, prompt, response):
log_entry = {
"user_id": user_id,
"timestamp": datetime.datetime.utcnow().isoformat(),
"prompt": prompt,
"response": response.json()["content"][0]["text"],
"model": "claude-3-5-sonnet-20241022",
"tokens": response.json()["usage"]["input_tokens"]
}
# データベースまたはログストレージに保存
save_to_audit_db(log_entry)監査ログの設計については、Claude Code 監査ログ実装ガイド で詳しく解説していますので、併せてご参照ください。
MCP(Model Context Protocol)による拡張
MCP は、Claude が外部ツールやデータソースにアクセスするための標準プロトコルです。社内データベースや API を Claude に接続することで、業務固有の情報を参照しながら回答を生成できます。DigiRise では、MCP を活用した顧客管理システムとの統合事例があります。
MCP の活用例: 社内 FAQ データベースへのアクセス権限を MCP 経由で Claude に付与し、問い合わせ対応の精度を向上させる。詳細は MCP 統合ガイド を参照
MCP の実装には、認可設計やデータアクセス範囲の明確化が求められます。特に、Claude に与える権限を必要最小限に制限し、機密情報への不要なアクセスを防ぐ設計が重要です。
Webhook 連携とイベント駆動設計
Claude API 自体は Webhook をネイティブにサポートしていませんが、業務システムとの統合では、イベント駆動型の設計が求められる場面があります。たとえば、ドキュメントがアップロードされたら自動で要約を生成し、結果を Slack に通知する、といったワークフローです。
Webhook 連携の実装パターン
# 疑似コード(Webhook トリガー)
from flask import Flask, request
app = Flask(__name__)
@app.route("/webhook/document-upload", methods=["POST"])
def handle_document_upload():
data = request.json
document_id = data["document_id"]
# ドキュメントを取得
document_text = fetch_document(document_id)
# Claude API で要約生成
summary = call_claude_api(f"以下の文書を要約してください:\n\n{document_text}")
# 結果を Slack に通知
notify_slack(summary)
return {"status": "processed"}この設計により、人手を介さずに定型業務を自動化できます。ただし、Webhook エンドポイントのセキュリティ(署名検証、IP 制限)を適切に設定することが前提です。
ストリーミングレスポンスの活用
Claude API は Server-Sent Events(SSE)形式のストリーミングレスポンスをサポートしており、生成途中の文章を逐次受け取ることができます。チャット UI など、リアルタイム性が重視される用途で有効です。
# 疑似コード(ストリーミング)
import sseclient
payload["stream"] = True
response = requests.post(ENDPOINT, headers=headers, json=payload, stream=True)
client = sseclient.SSEClient(response)
for event in client.events():
if event.event == "content_block_delta":
partial_text = event.data
# クライアントに逐次送信
send_to_client(partial_text)ストリーミングを使用する場合、フロントエンドとの WebSocket 接続や Server-Sent Events の実装が必要になるため、技術スタックに応じて適切な設計を選択する必要があります。
モニタリングと可観測性の確保
Claude API 連携を本番運用する際、システムの健全性を監視し、異常を早期に検知する仕組みが不可欠です。DigiRise が支援する案件では、以下の指標を重点的に監視しています。
監視すべき主要指標
| 指標 | 目的 | 取得方法 |
|---|---|---|
| レスポンス時間 | 応答遅延の検知 | ログから API 呼び出し〜応答受信の時間を計測 |
| エラー率 | 障害の早期検知 | HTTP 4xx/5xx の発生頻度を集計 |
| トークン消費量 | コスト管理 | API レスポンスの usage フィールドを記録 |
| スループット | 処理能力の把握 | 時間あたりのリクエスト数を集計 |
# 疑似コード(メトリクス記録)
from prometheus_client import Counter, Histogram
request_counter = Counter("claude_api_requests_total", "Total API requests")
error_counter = Counter("claude_api_errors_total", "Total API errors")
latency_histogram = Histogram("claude_api_latency_seconds", "API latency")
def call_claude_with_metrics(payload):
start_time = time.time()
request_counter.inc()
try:
response = requests.post(ENDPOINT, headers=headers, json=payload)
if response.status_code != 200:
error_counter.inc()
return response
finally:
latency = time.time() - start_time
latency_histogram.observe(latency)Prometheus + Grafana、Datadog、CloudWatch など、既存の監視基盤に Claude API のメトリクスを統合することで、他システムと横断的に監視できます。
アラート設計の考え方
アラートは 重要度に応じた段階的な通知 を設計します。たとえば、エラー率が5%を超えたら Slack 通知、10%を超えたら PagerDuty で担当者を呼び出す、といった段階的なエスカレーションが有効です。誤検知を防ぐため、一定期間の移動平均を基準とする設計も検討します。
まとめ
Claude API 連携では、以下の3点を明確にすることで、安定した運用基盤が整います。
同期連携・非同期連携・MCP 拡張・Webhook 統合など、複数のパターンを業務要件に応じて使い分けることで、柔軟なシステム構成が実現できます。エラーハンドリングとモニタリングを適切に設計すれば、長期的な運用負荷を抑えながら安定稼働が見込めます。
DigiRise では、法人向けの Claude Code API 連携設計を 研修プログラム と コンサルティング支援 の2本柱で提供しています。既存システムのアーキテクチャ分析から実装支援、運用体制の構築まで、貴社の技術スタックに応じた最適な統合設計をご提案します。Claude Code 法人導入ガイド では全体的な導入プロセスを解説していますので、併せてご確認ください。
無料相談では、現在の技術環境や要件をヒアリングし、適切な連携パターンをご提案しています。お気軽にお問い合わせください。